Executive Summary
Oursky was commissioned by a client to develop a machine learning-based algorithm to predict NBA game results. To achieve this goal, we built a tailored machine learning model to make predictions for NBA games – that is, predicting the probability of each team winning an NBA game, as well as presenting the rationale behind the predictions. We were able to outperform several other published models and predictions on FiveThirtyEight in both backtesting of NBA season (>67%) and in the first season of production use (>80%).
Through this case study, we will also illustrate how a typical artificial intelligence (AI) project works.
Challenges
What is the context and background?
Predictions and forecasts are some of the main applications of machine learning. By using statistical models and algorithms, machine learning can predict possible outcomes and trends. Many previous cases show that machine learning can help predict stock markets, forecast sales, and even improve patient care by predicting health conditions.
We decided to apply machine learning on predicting NBA game results. NBA is one of the most popular sports league in the world, so it is not surprising that NBA fans would be eager to know who will win in the NBA season. If accurate predictions on NBA game results could be done by utilizing machine learning, it will help create more excitement and engagement for NBA fans all over the world.
The two main objectives of this project are:
- Develop a machine learning model that predicts the win-loss probability of a team
- Interpret the “reasons” behind the predictions
Since Oursky team is full of NBA lovers, this project is very interesting to us. With both our expertise and solid experience in AI projects, we would love to explore the limits of how accurate we can predict NBA games, and to understand more about machine learning’s capability and limitations on making predictions. We can also further explore the opportunities of applying machine learning on more dynamic situations and create more business values with technology.
Solutions
How do you start AI projects?
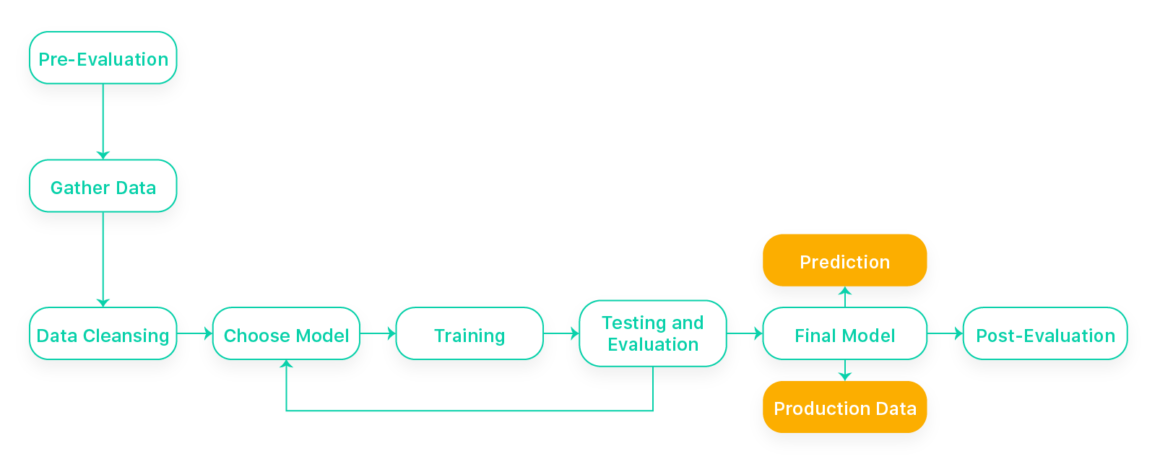
Many people may have thought of doing some AI projects but don’t know where to start. Below are some the typical procedures we undergo when starting an AI project:
- Pre-evaluation. For a machine learning project, the first step is usually evaluating the project idea and confirming if we have enough data for later training and testing. If the project or business idea comes from a client, we will normally analyze the case then come up with a proposal of two to three possible solutions on how AI can be applied to solve their issues.
- Gathering data. Depending on the nature of the project, we define what data is relevant to feed into the machine learning models. Datasets can be obtained from different sources, such as free, open data or paid database. Sometimes, there are projects that require internal data from our clients, too. For example, we developed a sales estimation and product recommendation model for a retail client in another AI project. The datasets would mostly consist of historic transaction records of the client.
- Data cleansing. Cleaning and organizing the raw data is required before performing any ML models. It helps us sort out missing or extreme values, noises, or potential data errors. Datasets will be further divided into training and testing.
- Choosing a model. After fully analyzing the project scope and data, we will determine which model/s could be used to proceed with training. We may try more than one model and experiment with different designs if the AI solutions don’t have a well-established model design that’s proven to be good enough.
- Training. For most supervised learning models, in order to train a model, we will feed the model with a batch of training data and optimize the model’s parameters during the process.
- Evaluation. Testing the dataset is used to validate if the built model provides meaningful results. A validation set of data will be fed to the trained model and test the accuracy. We will also evaluate how to modify the model during the training (i.e., optimize the parameters or choose another suitable model).
- Final modeling. If the concept is proven to work with desirable accuracy, we can consider it as the final model and use for production. If it is a client project, we will provide the final model to the client. The client can feed production data and make predictions with the final model afterwards.
- Post-Evaluation: At the end of the project, we will also generate a review report to conclude how we trained the models, along with the results and recommendation on how to optimize them in the long term.
Is there an accuracy commitment for machine learning prediction projects?
Nowadays, many machine learning projects are developed based on existing models. Hence, you can usually obtain a certain accuracy with a proven model. However, it is essential to understand the capabilities of a machine learning project and set the right expectation if you are starting your own one. For a new machine learning project that is being built from scratch, there is no guarantee for accuracy as we are yet to know the qualities of the training data, or if the data even correlate with the prediction result. Therefore, a completely new machine learning project should be regarded as a proof-of-concept (PoC) process (refer to the “black box” problem in the technical section below if interested).
In this project, we assumed that implicit information derived from historical NBA records is related to the probability of a team winning or losing an NBA game. The project goal is proving whether it is feasible to predict the result of NBA games with a scientific and systematic approach.
How does machine learning work in this project?
Following the aforementioned process, we worked out the NBA prediction project step by step:
- Pre-evaluation
- Deep learning, a subset of machine learning, has the strength to learn from raw input features in the hidden layer without domain knowledge. We therefore proposed a few models, which include team-based, player-based, and network-based approaches.
- Gathering Data and Data Cleansing
- For NBA predictions, we would like to predict the margin of victory (MOV) and the winner of the game. The margin of victory is a statistical-based calculation on the difference between scores of the winning team and the losing team, which helps determine the significance of the victory.
- We selected players’ logs of each game starting from 1983 (the first year where there is a full entry of box score) from Basketball Reference as data inputs.
- Each log involves box score and other information of the play in the game such as timestamp, experience, attempts, fouls, etc. We then proceeded to clean the data.
- Choosing Model and Training
- Since the MOV of a game does not necessarily represent the strength difference between the competing teams, it is ineffective to predict the MOV of a game. Practically, the probability distribution output by the classification model can be treated as the confidence level of which team is going to win. It is more understandable to interpret the probability distribution output as to how confident the model prediction is than the MOV output by the regression model. Please refer to this section for more technical details if you are interested.
- Evaluation
- We performed testing with a set of data from 2013 to 2017 with three different models in parameters initialization for comparison. It is proven that our models generally outperform FiveThirtyEight and are ready to feed with production data for predictions.
- Instead of just providing numbers, we further used the SHapley Additive exPlanations (SHAP) framework to give “reasoning” to the predictions to make the prediction results more appealing. Please refer to this section for further elaboration.
- Post-Evaluation
- At the end of the PoC, we generated an evaluation report to conclude the approach we tried, the way we trained the models, the accuracy of the predictions, and suggestions on how to further optimize results in the future.
Results
For the last NBA season, our model obtained an overall accuracy of 80%, which outperformed FiveThirtyEight. To further optimize the results, we are eager to try Temporal Convolutional Network (TCN) in future, which is more computationally efficient and robust than Recurrent Neural Network (RNN).
With the success of this project, we have validated the concept and foresee that the subject of machine learning projects could be potentially extended to other sporting events such as football and MLB.
If you are interested in making predictions for your business, or not sure how AI might help, you’re welcome to make an appointment with our professional AI consultants to explore different options.
Category
Technologies
Services
- Development
- Machine Learning Research
Features
- Prediction
- Forecasting
Optional Read
This section covers the technical details about various feasible approaches and models being used. This is recommended for those who have fundamental knowledge of machine learning.
Feasible Approaches
Considering the team and player as the two main entities in a basketball game, we studied three relevant approaches for forecasting:
- Team-based approach
- Team-based approach attempts to predict the game results by evaluating the general strength of a whole team. It aims to predict the MOV with a linear regression formula by deriving the difference in strength of the opposing teams. Other factors like home advantage and back-to-back games are also taken into consideration.
- Player-based approach
- Player-based approach takes team composition into account. It considers the strength of each player as a key factor determining the integrated strength of a team. FiveThirtyEight, a popular website providing NBA predictions with statistical analysis, also uses this approach. In this approach, the average playoff experience and Elo rating are the key factors.
- Network approach
- Network approach treats a sports league as a network of players, coaches, and teams. It utilizes the work relationships among networks to extract the implicit information of each team for forecasting the teams’ behavior. In this approach, the key factors include team volatility, roster aggregate volatility, team inexperience, roster aggregate coherence, roster size, etc.
Machine Learning Models
NBA is an extremely dynamic game with many attributes, and using any one model may not be promising enough. We therefore proposed to use a deep learning algorithm for this project. Deep learning is a subset of machine learning and is generally being used to teach machines to identify patterns or classify information.
We developed our machine learning model with two predictive models:
- Regression
- To predict the MOV (scores difference between home and away team), we treated it as a regression problem. We modeled the MOV as a function of the inputs (players’ logs of the NBA games) and trained the neural network to predict the MOV. When the MOV is positive, it implies that the home team is likely to win.
- Classification
- To predict which team is going to win, we classified the NBA game as a home team winning or losing to forecast the winner of a game with great confidence. This model will output a probabilistic distribution of whether a game belongs to a category of the home team winning or losing the game.
- Different from regression where the output is a linear activation function, a softmax function, in classification, will be used as the output of the network. This is done so that it is able to provide a normalized vector of the probabilistic distribution of different classes.
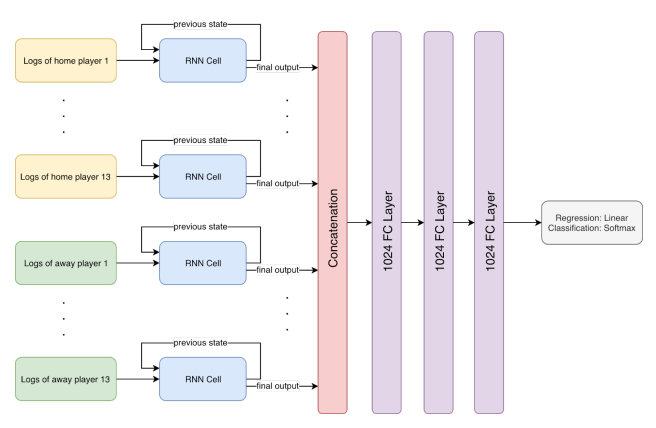
For both models, they share the same RNN for player strength encoding. RNN is a type of neural network designed to model sequential data including text and stock price. We treated the players’ logs as time series data that can be inputted to the RNN cell. To overcome the vanishing and exploding gradient problem, we used long short-term memory (LSTM) cell instead of a generic RNN cell.
We tested window sizes ranging from 1 to 200 for the optimal window size. Furthermore, the model accuracy is also tested with data from 2017.
We built a network map which shows 26 players’ logs passing through the RNN with weights shared among all the inputs. Three LSTM cells are used in the RNN and the output is a vector of 256-dimension. The output vectors are then concatenated together and fed to a fully connected network of three layers with 1024 nodes each.
Explaining the Prediction Result
Explanation is important for validating that the predictions are not just some numbers made with a blind guess. However, explaining prediction results is somehow difficult.
“Black Box” is considered a common problem of deep learning algorithms (deep learning is a subset of machine learning). Simply put, deep learning creates its own understanding of the hierarchical architecture of neurons. Therefore, it is difficult to inspect how deep learning algorithms analyzed the data and accomplished the assigned task. To overcome the black box problem, SHAP, a general framework to interpret machine learning models by visualization, is a possible solution.
By applying this framework, we are able to quantify the contribution of each input parameter to the prediction result with an activation heat map. Then we can analyse the activation heat map to figure out the most critical parameter.